The one thing you need to understand about Apache Spark APIs (Python, Scala, Java, SQL)
Apache Spark offers multiple programming interfaces to write applications, which process large amounts of data distributively. While Spark itself is written in Scala, it provides APIs for Scala, Python, Java and R. These, of course, are programming languages we use together with an external dependency to write Spark code. However, there is one additional player, which occupies kind of a unique role: SQL. SQL is a declarative query language, used to describe transformations on data, using a specific set of keywords.
Is there a difference regarding performance, monitoring or debugging?
Now, as we have learned, we can use SQL to implement an Apache Spark application. The question is: Is there any difference with regard to performance, debuggability or monitoring whether I use a programming language oder SQL?
TL;DR: No, there isn't. That's simply because internally, Spark uses the very same functionality, no matter which API you use.
If that's the answer you were looking for, you can stop reading here. However, if you'd like to understand how things work - keep on reading.
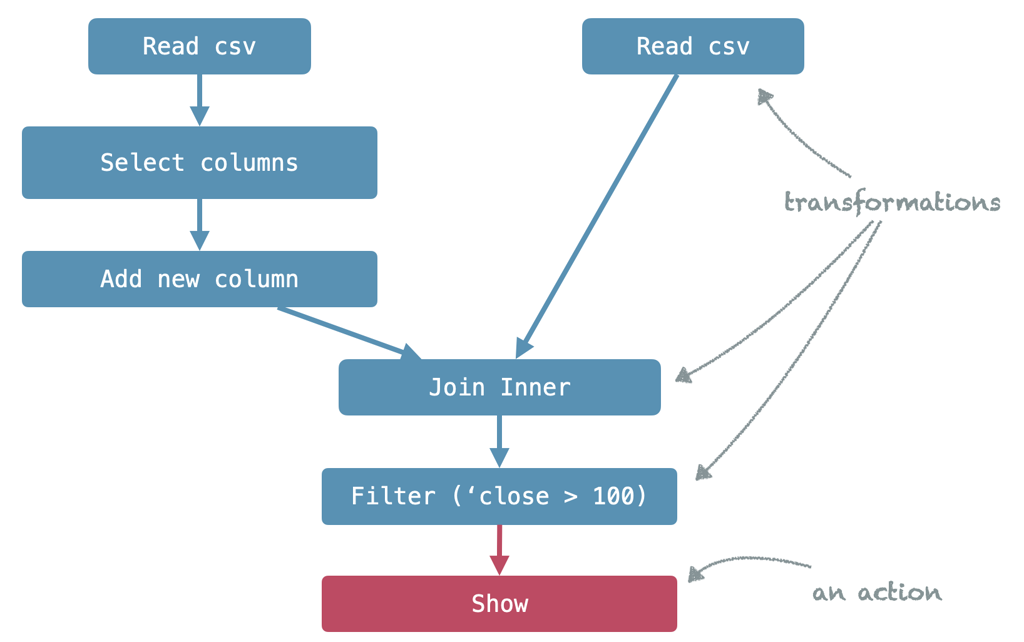
Spark's execution model works with an abstract, logical representation of the query
As we implement an Apache Spark application, say with Scala, we use an external library that provides us with classes and objects we can use to tell Spark how we would like to transform the data.
That's what we call the API – because it allows us to access Spark's execution model from within our Scala code.
However, the Spark SQL API (generally) is heavily inspired by SQL language features.
The main abstraction we use to represent data is the DataFrame.
We can call transformations and actions on a DataFrame to implement our logic.
What happens internally is that Spark assembles an abstract, logical representation of the query we build.
This internal representation is called the Logical Plan and consists of the operators, their order, inputs and attributes used within our program.
It is independent of the programming language we used to assemble it.
The Logical Plan contains all information required to evaluate the result of a query on a distributed cluster.
Writing SQL queries requires interpretation
So far so good, but what happens if we use SQL to implement a Spark workload? Well, everything is quite the same. However, we need to add an additional step before we can start to assemble the Logical Plan. As we hand Spark an SQL query which is simply a string, we need to parse it into the components used. We can say that Spark actually implements an entire SQL interpreter to transform a string representation of an SQL query into its own internal logical representation – in other words: the Logical Plan.
Now, coming back to our initial question, whether it makes a difference in terms of performance, monitoring, deployment or otherwise - the answer is simple: No, it doesn't.
Using SQL comes at a cost
Having that said, from my point of view, there is a large downside in using SQL queries to run Spark. Writing SQL queries as text, takes away many advantages writing properly typed code would have:
- Many useful IDE features: Code completion & refactorings
- Compile-time safety
- Writing clean code by refactoring it into well-readable and testable pieces.